One of the big reasons I have been using ChatGPT lately has been to get it to produce diverse datasets for my Computing classes. With Data Mining being a prominent presence in the IB’s version of the program, here are some basic ways in which I have explored this new (and fascinating!) AI tool.
Context based datasets
To assist students with understanding Data Warehouses and the ETL (Extract -> Transform -> Load) processes, I had GPT create a few randomized datasets based on different contexts. Here are a few of them.
I began by asking it a pretty generic question.

The response came back as a JSON file which I can then use to read via a script.

I then queried it further to convert this into a table. And this is what I got.

This table can now be transformed in various ways to reflect upon how to deal with:
- Missing information.
- Inconsistent / redundant data pieces.
- Unnormalized structure in need of normalization.
I now tried to use a realistic context for the same data and tried asking it the following.

And here is what I got as a response.

As you can perhaps tell, the data presented here is indeed inconsistent and presents an opportunity for massive improvements in terms of formatting, data integrity and normalization. Students have also found this exercise of brainstorming ideas around some of the social and ethical nature of collecting such data useful. For instance, why is gender being collected as part of this set? Or, how would it be used? Or, what impact would the data set’s quality have if gender column were to be removed?
Finally, in an effort to keep the data set locally relevant, I tried adding a regional setting to it so students can further benefit from the experience.

A few tweaks in the question on numerical nature of the data produced this.
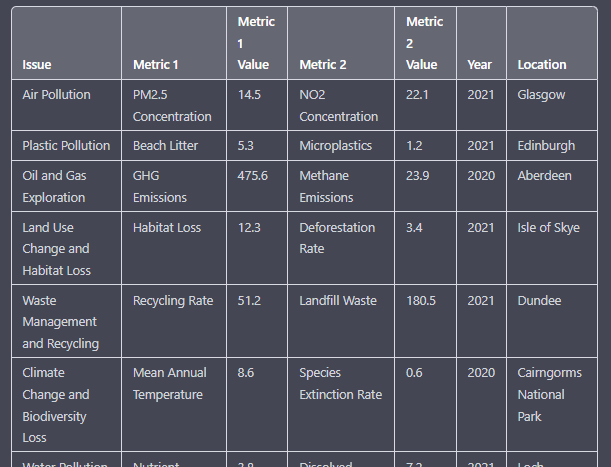
I then asked it to make a source column for authenticity.

And here is the output. Such data sets can be tweaked further to have repeated/redundant values to help students understand some areas of cleaning up data sources.

Finally, I also got it to create a data set for link analysis by creating fictitious call log entries. The scenario was that of a crime being investigated by detectives.

Using this data set we explored a I notice, I wonder activity where students tried connecting source callers with both call duration and person whom they called. This allowed them to further explore the concept of link analysis in data mining.
Starting Points
These were some of the primary ways in which I have been using the data set generation capacity of ChatGPT. I hope to extend this into complete JSON files which can be read into and processed by different kinds of script based files such as JavaScript or Python. More on that to follow!
